qr_mumps
Table of Contents
News
-
qr_mumpsv 3.1 released (Changelog) -
qr_mumpsv 3.0.4 released (Changelog) -
qr_mumpsv 3.0.3 released (Changelog) -
qr_mumpsnow has a Julia interface! It is available HERE. Thanks to Alexis Montoison for developing it. -
qr_mumpsv 3.0.2 released (Changelog) -
qr_mumpsv 3.0.1 released (Changelog) -
qr_mumpsv 3.0 released (Changelog) -
qr_mumpsv 2.0 released (Changelog) -
qr_mumpsv 1.2 released (Changelog)
Overview
qr_mumps is a software package for the solution of sparse, linear
systems on multicore computers. It implements a direct solution
method based on the QR or Cholesky factorization of the input
matrix. Therefore, it is suited to solving sparse least-squares
problems, to computing the minimum-norm solution of sparse,
underdetermined problems and to solving symmetric, positive-definite
sparse linear systems. It can obviously be used for solving square
unsymmetric problems in which case the stability provided by the use
of orthogonal transformations comes at the cost of a higher
operation count with respect to solvers based on, e.g., the LU
factorization such as MUMPS. qr_mumps supports real and complex,
single or double precision arithmetic. qr_mumps
As in all the sparse, direct solvers, the solution is achieved in three distinct phases:
- Analysis
- in this phase an analysis of the structural properties of the input matrix is performed in preparation for the numerical factorization phase. This includes computing a column permutation which reduces the amount of fill-in coefficients (i.e., nonzeroes introduced by the factorization). This step does not perform any floating-point operation and is, thus, commonly much faster than the factorization and solve (depending on the number of right-hand sides) phases.
- Factorization
- at this step, the actual \(QR\) or Cholesky factorization is computed. This step is the most computationally intense and, therefore, the most time consuming.
- Solution
- once the factorization is done, the factors can be
used to compute the solution of the problem through
two operations:
- Solve
- this operation computes the solution of the triangular system \(Rx=b\) or \(R^Tx=b\);
- Apply
- this operation applies the \(Q\) orthogonal matrix to a vector, i.e., \(y = Qx\) or \(y = Q^Tx\).
These three steps have to be done in order but each of them can be performed multiple times. If, for example, the problem has to be solved against multiple right-hand sides (not all available at once), the analysis and factorization can be done only once while the solution is repeated for each right-hand side. By the same token, if the coefficients of a matrix are updated but not its structure, the analysis can be performed only once for multiple factorization and solution steps.
qr_mumps is a parallel, multithreaded software based on the StarPU
runtime engine (older versions based on OpenMP are still available
for download) and currently runs on multicore or, more generally,
shared memory multiprocessor computers; Nvidia GPUs are also
supported since version 3.0. qr_mumps does not run on
distributed memory (e.g. clusters) parallel computers. Parallelism
is achieved through a decomposition of the workload into
fine-grained computational tasks which basically correspond to the
execution of a BLAS or LAPACK operation on blocks. It is strongly
recommended to use sequential BLAS and LAPACK libraries and let
qr_mumps have full control of the parallelism. Parallelism is
achieved by dividing the workload into fine grained tasks that are
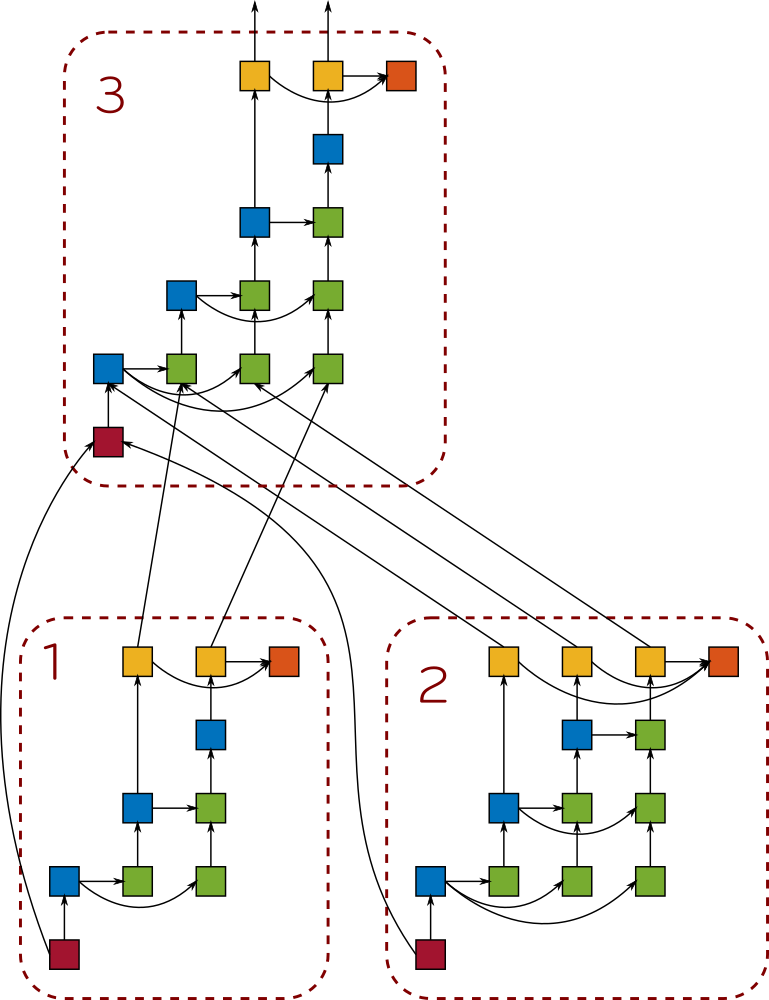
arranged in a Direct Acyclic Graph (DAG). The execution of these
tasks is guiged by an asynchronous and dynamic data-flow programming
model which provides high efficiency and scalability.
qr_mumps is built upon the large knowledge base and know-how developed
by the members of the MUMPS project. However, qr_mumps does not share
any code with the MUMPS package and it is a completely independent
software. qr_mumps is developed and maintained
effort by the APO team of the IRIT laboratory of Toulouse and the
HiePACS team at Inria Bordeaux, France.
Features:
- Supports unsymmetric, possibly rectangular problems through the \(QR\) factorization and symmetric positive-definite problems. through the Cholesky one.
- Task-based parallelism based on the StarPU runtime system
- Supports multicore systems possibly equipped with Nvidia GPUs.
- Orderings:
qr_mumpssupports COLAMD, Scotch and Metis fill-reducing orderings. Orderings can also be explicitly provided through theqr_mumpsAPI. - Memory constrained execution: the memory consumption of the parallel code can be bound by any (small) multiple of the sequential execution.
- Asynchronous interface: operations can be pipelined for additional parallelism.
- C interface:
qr_mumpsis written in Fortran 2008 but has a portable C interface.
Download
The lastest qr_mumps version can be downloaded here .
Alternatively, you can get it from the gitlab repo.
qr_mumps can also be installed through Guix or Spack.
Credits
- Emmanuel Agullo (Concace, Inria Sud-Ouest)
- Alfredo Buttari (APO, CNRS-IRIT)
- Abdou Guermouche (Topal, Universite de Bordeaux)
- Florent Lopez (Ansys)
Acknowledgments
- The design of
qr_mumpsis deeply influenced by the countless advices from Patrick Amestoy, Jean-Yves L'Excellent and Chiara Puglisi, the developers of the MUMPS and HSL MA49 solvers. - We are also grateful to the StarPU development team for their constant support in the use of this runtime system.
- Thanks Arnaud Legrand, Lucas Schnorr and Luka Stanisic for their feedback on performance analysis through SimGrid and StarVZ.
qr_mumpswas partially funded by the ANR SOLHAR and SOLHARIS projects.- The development, testing and performance evaluation of
qr_mumpsare possible thanks to the computing resources provided by the CALMIP and PlaFRIM supercomputing centers as well as those of the GENCI consortium. - Thanks to Alexis Montoison for developing the
qr_mumpsJulia interface.
Publications
Articles in journals or conference proceedings
| [1] | Alfredo Buttari, Søren Hauberg, and Costy Kodsi. Parallel qr factorization of block-tridiagonal matrices. SIAM Journal on Scientific Computing, 42(6):C313--C334, 2020. [ DOI | arXiv | http ] |
| [2] | Gabriel Hautreux, Alfredo Buttari, Arnaud Beck, Victor Cameo, Dimitri Lecas, Dominique Aubert, Emeric Brun, Eric Boyer, Fausto Malvagi, Gabriel Staffelbach, Isabelle d'Ast, Joeffrey Legaux, Ghislain Lartigue, Gilles Grasseau, Guillaume Latu, Juan Escobar, Julien Bigot, Julien Derouillat, Matthieu Haefele, Nicolas Renon, Philippe Parnaudeau, Philippe Wautelet, Pierre-Francois Lavallee, Pierre Kestener, Remi Lacroix, Stephane Requena, Anthony Scemama, Vincent Moureau, Jean-Matthieu Etancelin, and Yann Meurdesoif. Pre-exascale architectures: Openpower performance and usability assessment for french scientific community. In Julian M. Kunkel, Rio Yokota, Michela Taufer, and John Shalf, editors, High Performance Computing: ISC High Performance 2017 International Workshops, DRBSD, ExaComm, HCPM, HPC-IODC, IWOPH, IXPUG, P3MA, VHPC, Visualization at Scale, WOPSSS, Frankfurt, Germany, June 18-22, 2017, Revised Selected Papers, pages 309--324, Cham, 2017. Springer International Publishing. [ DOI | arXiv | http ] |
| [3] | Emmanuel Agullo, George Bosilca, Alfredo Buttari, Abdou Guermouche, and Florent Lopez. Exploiting a parametrized task graph model for the parallelization of a sparse direct multifrontal solver. In Frédéric Desprez, Pierre-François Dutot, Christos Kaklamanis, Loris Marchal, Korbinian Molitorisz, Laura Ricci, Vittorio Scarano, Miguel A. Vega-Rodríguez, Ana Lucia Varbanescu, Sascha Hunold, Stephen L. Scott, Stefan Lankes, and Josef Weidendorfer, editors, Euro-Par 2016: Parallel Processing Workshops: Euro-Par 2016 International Workshops, Grenoble, France, August 24-26, 2016, Revised Selected Papers, pages 175--186, Cham, 2017. Springer International Publishing. [ DOI | arXiv | http ] |
| [4] | Emmanuel Agullo, Alfredo Buttari, Abdou Guermouche, and Florent Lopez. Implementing multifrontal sparse solvers for multicore architectures with sequential task flow runtime systems. ACM Trans. Math. Softw., 43(2):13:1--13:22, August 2016. [ DOI | arXiv | http ] |
| [5] | Emmanuel Agullo, Olivier Beaumont, Lionel Eyraud-Dubois, Julien Herrmann, Suraj Kumar, Loris Marchal, and Samuel Thibault. Bridging the Gap between Performance and Bounds of Cholesky Factorization on Heterogeneous Platforms. In Heterogeneity in Computing Workshop 2015, Hyderabad, India, May 2015. [ http ] |
| [6] | Luka Stanisic, Emmanuel Agullo, Alfredo Buttari, Abdou Guermouche, Arnaud Legrand, Florent Lopez, and Brice Videau. Fast and accurate simulation of multithreaded sparse linear algebra solvers. In Parallel and Distributed Systems (ICPADS), 2015 IEEE 21st International Conference on, pages 481--490, Dec 2015. [ DOI ] |
| [7] | Emmanuel Agullo, Alfredo Buttari, Abdou Guermouche, and Florent Lopez. Task-based multifrontal QR solver for GPU-accelerated multicore architectures. In HiPC, pages 54--63. IEEE Computer Society, 2015. Best paper award. [ DOI | arXiv ] |
| [8] | Alfredo Buttari. Fine-grained multithreading for the multifrontal QR factorization of sparse matrices. SIAM Journal on Scientific Computing, 35(4):C323--C345, 2013. [ DOI | arXiv | http ] |
| [9] | Alfredo Buttari. Fine granularity sparse QR factorization for multicore based systems. In Proceedings of the 10th international conference on Applied Parallel and Scientific Computing - Volume 2, PARA'10, pages 226--236, Berlin, Heidelberg, 2012. Springer-Verlag. [ DOI | http ] |
This file was generated by bibtex2html 1.99.
Talks and Technical reports
| [1] | Emmanuel Agullo, Alfredo Buttari, Abdou Guermouche, Ian Masliah, and Luka Stanisic. Simulation of a task-based sparse direct solver, February 2019. Presentation at the SIAM CSE 2019 conference. |
| [2] | Emmanuel Agullo, Alfredo Buttari, Abdou Guermouche, and Ian Masliah. qr_mumps: a runtime based sparse direct solver for heterogeneous architectures, June 2018. Presentation at the PMAA 2018 conference. |
| [3] | Emmanuel Agullo, Alfredo Buttari, Abdou Guermouche, and Ian Masliah. qr_mumps: a runtime-based sequential task flow parallel solver, October 2017. Presentation at the EoCoE workshop. |
| [4] | Emmanuel Agullo, Alfredo Buttari, Mikko Byckling, Abdou Guermouche, and Ian Masliah. Achieving high-performance with a sparse direct solver on Intel KNL. Research Report RR-9035, Inria Bordeaux Sud-Ouest,CNRS-IRIT,Intel corporation,Université Bordeaux, February 2017. [ http ] |
| [5] | Emmanuel Agullo, George Bosilca, Alfredo Buttari, Abdou Guermouche, and Florent Lopez. Experiments with multifrontal qr using a ptg model, August 2016. Presentation at the EuroPar-16 conference. |
| [6] | Emmanuel Agullo, Alfredo Buttari, Abdou Guermouche, and Florent Lopez. Task-based multifrontal qr solver for gpu-accelerated multicore architectures, 2015. Presentation at the Sparse Days in St Girons international conference, St Girons, June 29 - July 2 2015. |
| [7] | Emmanuel Agullo, Alfredo Buttari, Abdou Guermouche, and Florent Lopez. Sparse direct solvers on top of a runtime system, 2015. Presentation at the SIAM Computational Science and Engineering international conference, Salt Lake City, March 14-18 2015. |
| [8] | Emmanuel Agullo, Olivier Aumage, George Bosilca, Berenger Bramar, Alfredo Buttari, Olivier Coulaud, Eric Darve, Jack Dongarra, Mathieu Faverge, Nathalie Furmento, Luc Giraud, Abdou Guermouche, Julien Langou, Florent Lopez, Hatem Ltaief, Samuel Pitoiset, Florent Pruvost, Marc Sergent, Samuel Thibault, and Stanimire Tomov. Matrices over runtime systems at exascale, 2015. Poster at the SuperComputing 2015 conference. |
| [9] | Emmanuel Agullo, Alfredo Buttari, Abdou Guermouche, and Florent Lopez. Sparse direct solvers on top of a runtime system, 2014. Presentation at the PMAA 2014 international conference, Lugano July 2-4 2014. |
| [10] | Emmanuel Agullo, Alfredo Buttari, Abdou Guermouche, and Florent Lopez. Multifrontal QR factorization for multicore architectures over runtime systems, 2013. Presentation at the Euro-Par 2013 international conference, Aachen August 26-30 2013. |
| [11] | Alfredo Buttari. Fine grained sparse QR factorization for multicore systems, June 2011. Poster at The Householder Symposium 2011. |
This file was generated by bibtex2html 1.99.